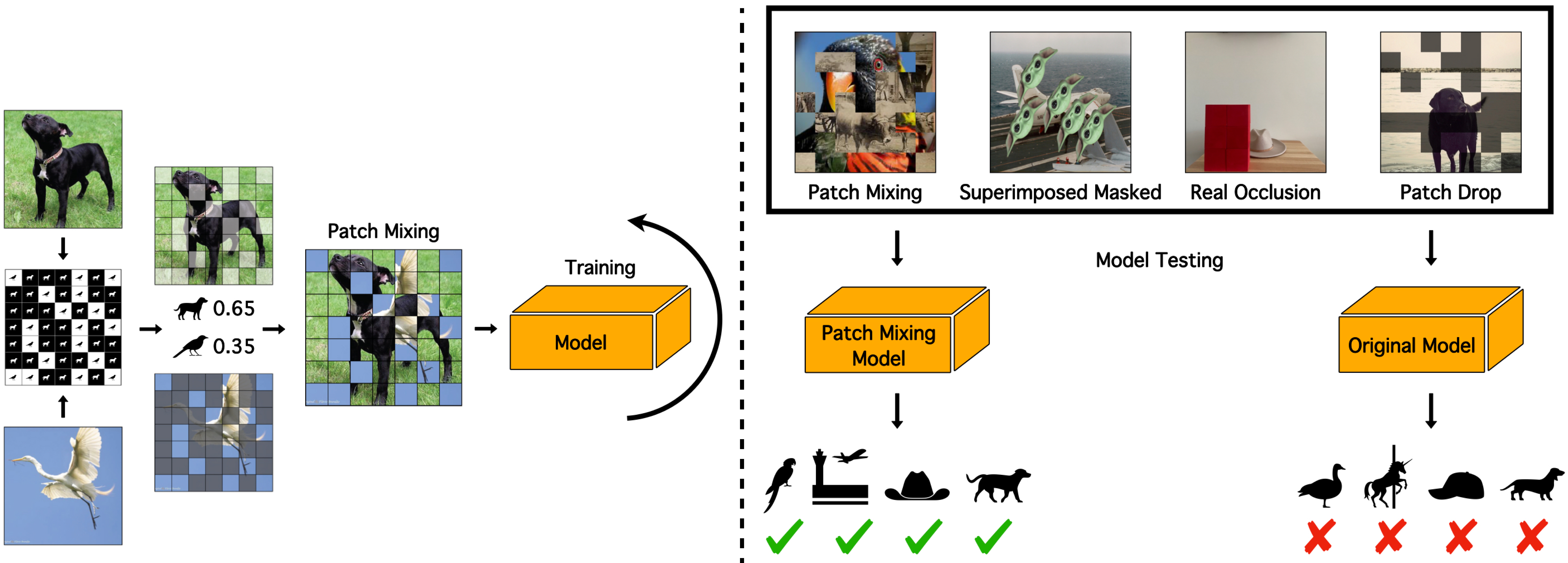
[Paper] [Superimposed Masked Dataset] [Realistic Occlusion Dataset] [Code (soon)]
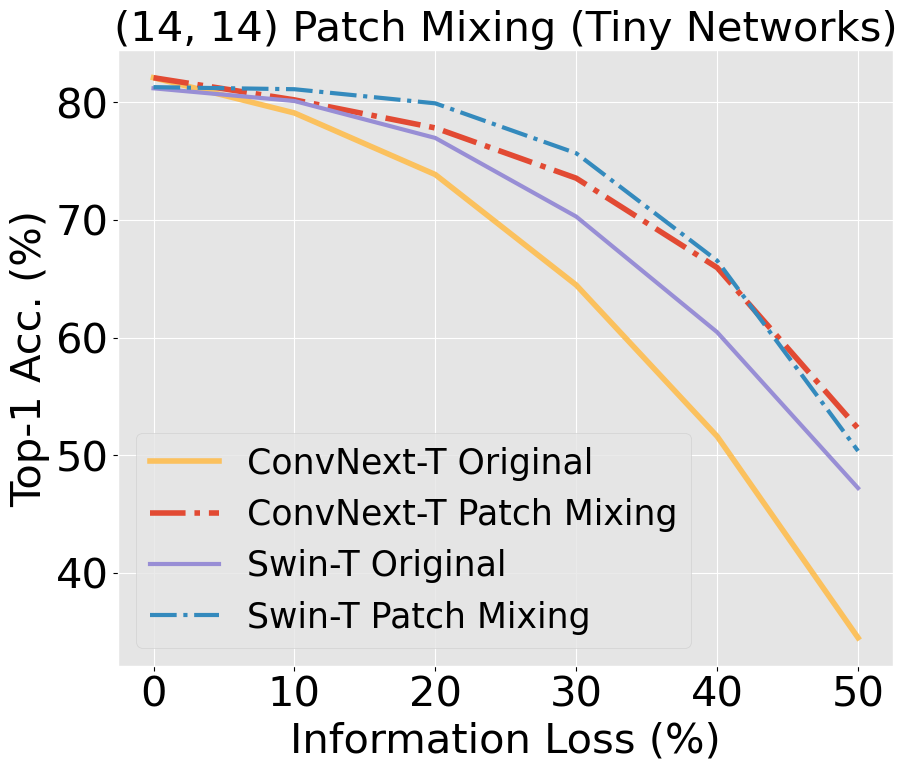
Vision transformers (ViTs) have significantly changed the computer vision landscape and have periodically exhibited superior performance in vision tasks compared to convolutional neural networks (CNNs). Although the jury is still out on which model type is superior, each has unique inductive biases that shape their learning and generalization performance. For example, ViTs have interesting properties with respect to early layer non-local feature dependence, as well as self-attention mechanisms which enhance learning flexibility, enabling them to ignore out-of-context image information more effectively. We hypothesize that this power to ignore out-of-context information (which we name patch selectivity), while integrating in-context information in a non-local manner in early layers, allows ViTs to more easily handle occlusion. In this study, our aim is to see whether we can have CNNs simulate this ability of patch selectivity by effectively hardwiring this inductive bias using Patch Mixing data augmentation, which consists of inserting patches from another image onto a training image and interpolating labels between the two image classes. Specifically, we use Patch Mixing to train state-of-the-art ViTs and CNNs, assessing its impact on their ability to ignore out-of-context patches and handle natural occlusions. We find that ViTs do not improve nor degrade when trained using Patch Mixing, but CNNs acquire new capabilities to ignore out-of-context information and improve on occlusion benchmarks, leaving us to conclude that this training method is a way of simulating in CNNs the abilities that ViTs already possess. We will release our Patch Mixing implementation and proposed datasets for public use.
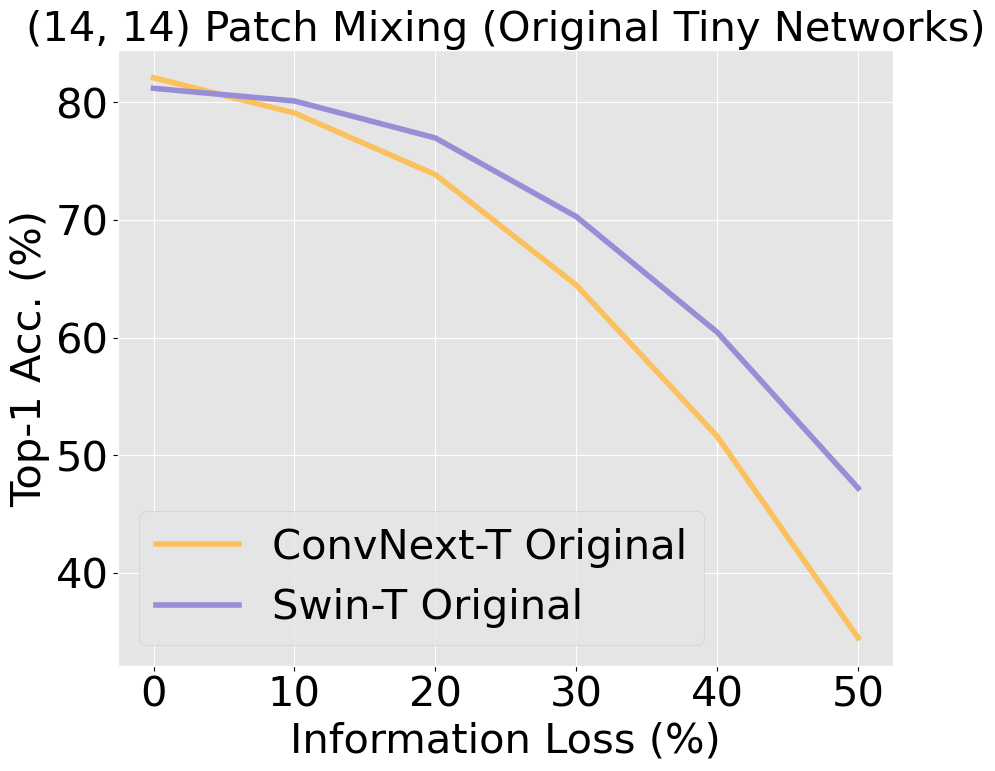
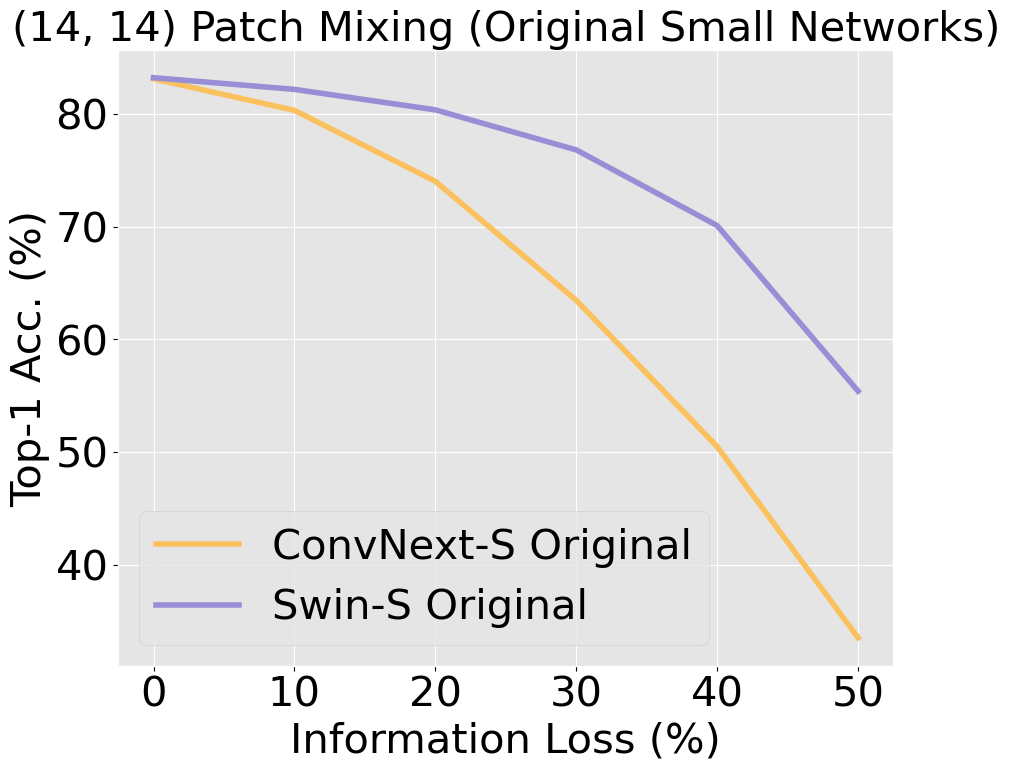
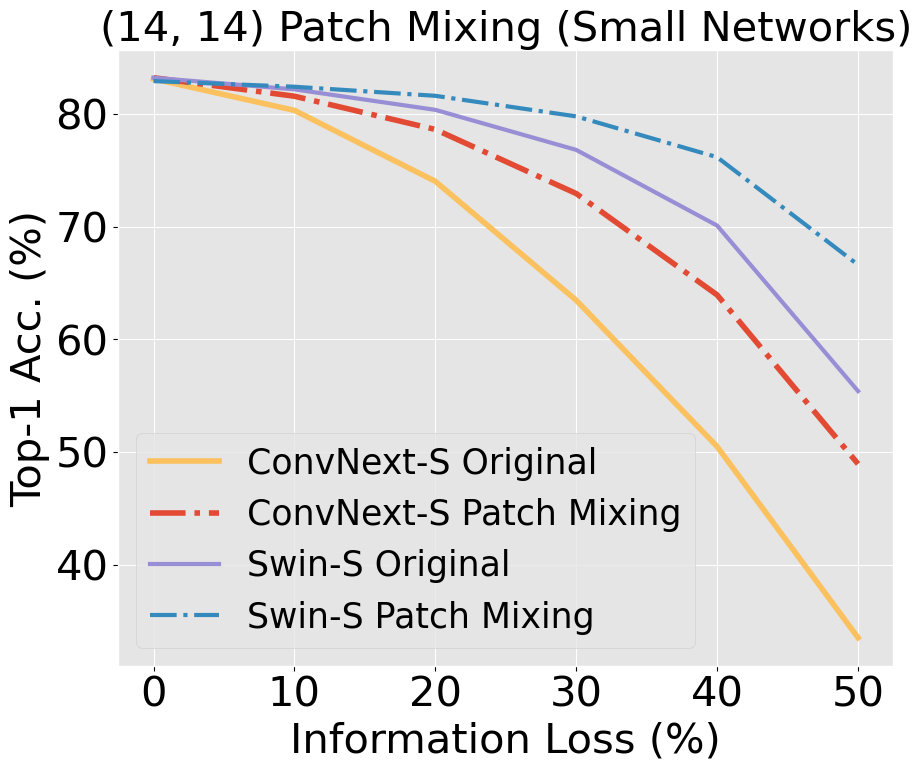
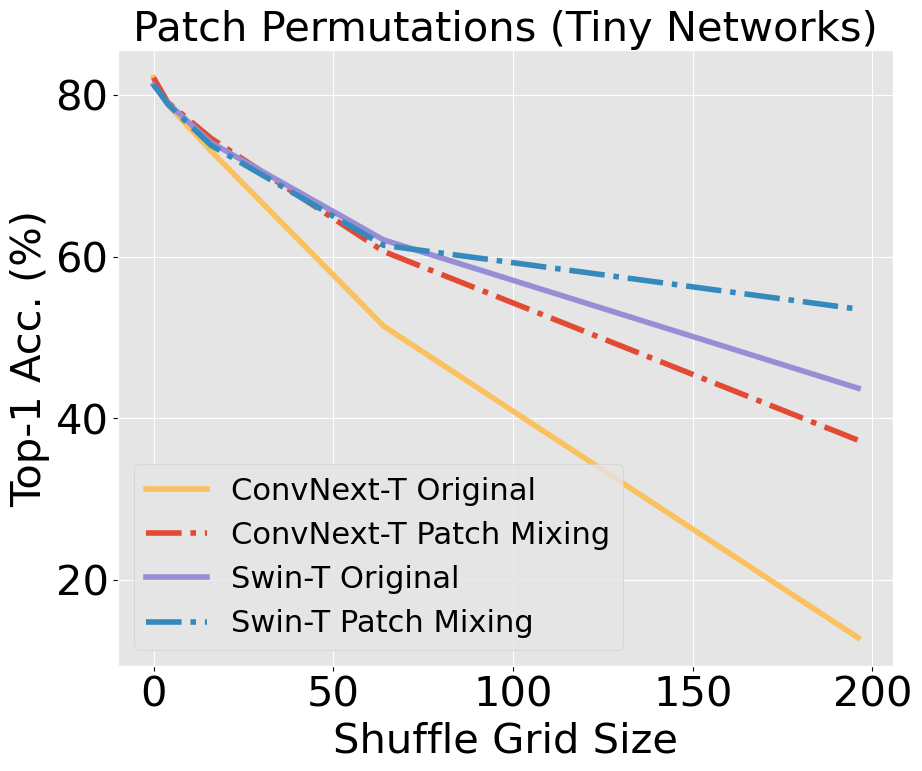
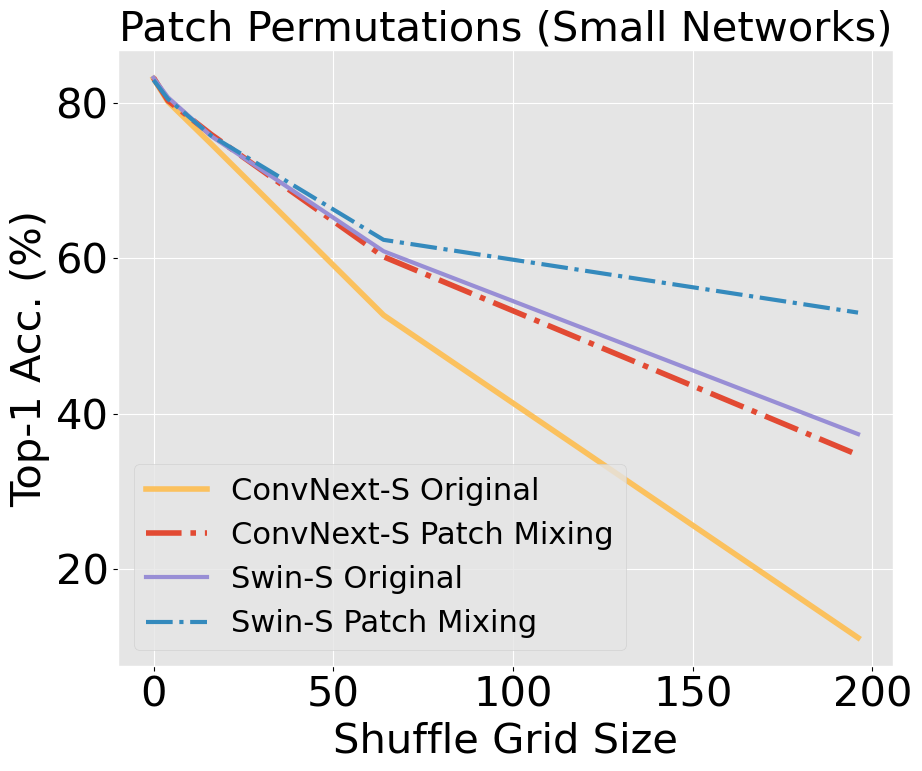
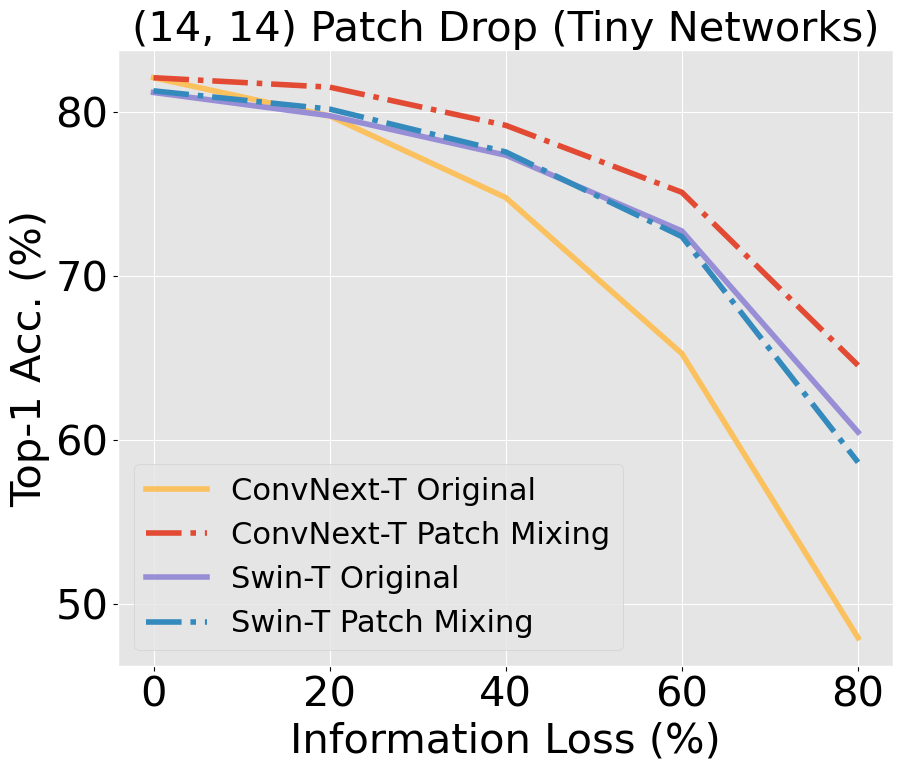
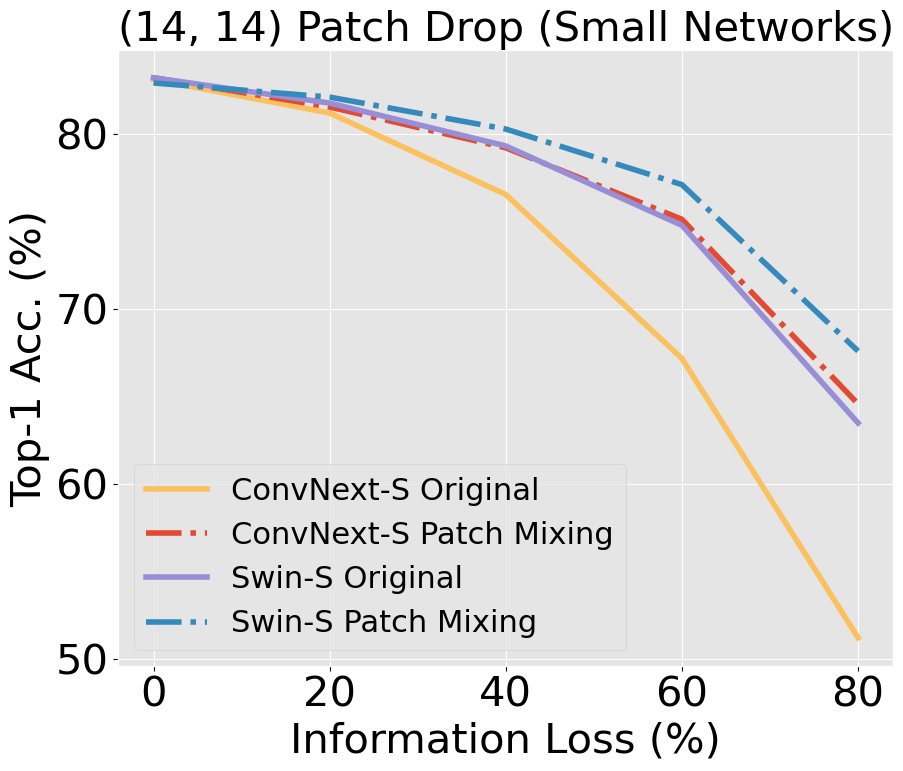
Unlike CNNs with receptive fields determined by kernel size and stride, ViTs leverage self-attention, allowing all pixels to be accessible from the get-go. This introduces an early-layer long-range dependency not structurally feasible in CNNs, even those with modern patchify stems. ViTs' hierarchical attention potentially makes them superior at discounting out-of-context image information compared to CNNs, which are burdened by structural and inductive biases. Our research scrutinizes this hypothesis, building on findings [Naseer et al., 2022] that demonstrated the superior capability of ViTs relative to older CNN architectures when handling simulated occlusion via patch drop experiments. We show that compared to modern convnets, ViTs experience a smaller decrease in accuracy when out-of-context patches are introduced. In the figure below, we see a larger decrease in accuracy in ConvNeXt compared to Swin, with a widening gap as information loss increases.
Patch Mixing creates a new image-label pair, \((\tilde{x}, \tilde{y})_i\), from an image, \(x \in \mathbb{R}^{H \times W \times C}\), and its respective label, \(y\). This is achieved by merging patches from two images, \(x_A\) and \(x_B\). We form a mask, \(M \in {0, 1}^{N \times P^2 \times C}\), where \((H, W)\) is the original image resolution, \(C\) denotes channels, \((P, P)\) is each patch's resolution, and \(N = \frac{HW}{P^2}\) gives the number of patches. The mask is initially set to \(0\) and then we randomly choose \(N_1\) patches, setting them to \(1\). These patches replace their counterparts in image \(x_A\), with \(N_1\) dictated by a proportion hyperparameter \(r = N_1 / N\), which represents the proportion of replacement patches. We also blend labels \(y_A\) and \(y_B\) using proportion \(r\) to form \(\tilde{y}\) and smooth the final vector with label smoothing [Szegedy et al., 2016]. Finally, \(\tilde{x}\) is generated as:
\[ \tilde{x} = (1 - M) \odot x_A + M \odot x_B \]
→



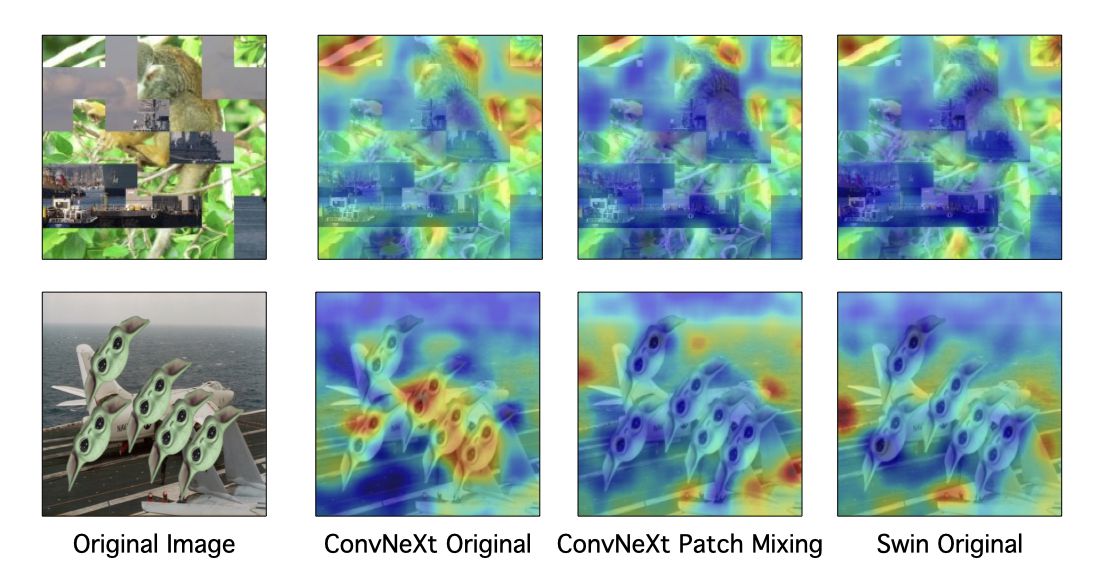
SMD is an occluded ImageNet-1K validation set meant to serve as an additional way to evaluate the impact of occlusion on model performance. This experiment used a variety of occluder objects that are not in the ImageNet-1K label space and are unambiguous in relationship to objects that reside in the label space. The occluder objects were segmented using Meta's Segment Anything [Kirillov et al., 2023]. In addition to images, we provide segmentation masks for reconstruction of occluder objects. We also release the code used to generate SMD, so our work can be easily replicated with other occluder objects and/or datasets. The occluders shown below from left to right, starting from the top row: Grogu (baby yoda), bacteria, bacteriophage, airpods, origami heart, drone, diamonds (stones, not setting) and coronavirus.







ROD is the product of a meticulous object collection protocol aimed at collecting and capturing 40+ distinct objects from 16 classes. Occluder objects are wooden blocks or square pieces of cardboard, painted red or blue. The occluder object is added between the camera and the main object and its x-axis position is varied such that it begins at the left of the frame and ends at the right. The objects below from left to right, starting with the top row: baseball, orange, spatula, banana, cowboy hat, dumbbell, skillet, and cup.








@misc{lee2023hardwiring,
title={Hardwiring ViT Patch Selectivity into CNNs using Patch Mixing},
author={Ariel N. Lee and Sarah Adel Bargal and Janavi Kasera and Stan Sclaroff and Kate Saenko and Nataniel Ruiz},
year={2023},
eprint={2306.17848},
archivePrefix={arXiv},
primaryClass={cs.CV}
}